Lad os snuble gennem kyberrummet sammen

Den tilhørende webprofil, men det er toolbaren der er selve fundamentet
Sjovt at Twitter får så meget omtale og StumbleUpon lever relativt anonymt, men dog stadig formår at have 50% flere brugere.
Jeg begyndte først selv, at bruge StumbleUpon for et par måneder siden, men må så til gengæld indrømme, at jeg siden da har fået et nyt, fast morgen ritual.
Jeg står op 45 min. tidligere end jeg plejer og laver en god kop kaffe. Og så sidder jeg ellers i den fredlige morgenstilhed og Stumbler af hjertets lyst.
I disse to (morgen)måneder har jeg opdaget flere nye, fantastiske artikler, fotos/illustrationer og sites end … tja meget! længe.
For mig er netop enkeltheden ved StumbleUpon’s tilhørende toolbar det helt afgørende. Jeg behøver ikke beslutte om jeg vil følge et uigennemskueligt tinyurl-link i Twitter jeg reloader bare løbende med alt+esc indtil jeg falder over noget godt.
I og med jeg ofte har en del faneblade kørende samtidigt i Firefox (jeg venter stadig! på Chrome til Mac) og løbende “tabber” igennem dem, mens nogle sider reloader, eller nye sider åbner, bliver mine stumbles noget der næsten nærmer sig peripheral sensing. Og lige netop dét er en personlig kæphest for mig i forbindelse med interaktions-design til web og “nye medier”.
Når jeg blæser gennem mine browserfaner og intuitivt fornemmer noget interessant giver jeg det opmærksomhed og hvis ikke det fanger med det samme lukker jeg fanen eller alt-esc’er en ny stumble.
Indrømmet det egner sig nok bedst til “visuelle” emner som fotos, design, arkitektur, illustration etc., hvor man ikke nødvendigvis behøves at nærlæse, men kan nøjes med at skimme siderne. Men så fungerer det til gengæld også bare perfekt. Simpel interaktion (inkl. mulighed for at sende links videre til min Gmail med 2 klik), et stort indholdskatalog og kollaborativ filtrering fra andre der har bedømt siderne før mig, er en vindercocktal når det fungerer.
Den grundliggende brugeroplevese er ubesværet og bliver ikke forstyrret af unødvendigt opmærksomhedskrævende valg i forbindelse med interaktion og navigation. Vi befinder under alle omstændigheder i en informations tsunami. Giv os da mulighed for at svømme med strømmen i stedet for at skulle kæmpe imod og forsøge at styre det ustyrlige. Måske endnu en smule overdrevet, men fremtiden er jo som bekendt bare ujævnt distribueret 😉
Udfordringen jeg dog er blevet opmærksom på efterhånden som jeg er blevet så glad for tjenesten, at jeg gerne vil yde mit bidrag til indholdskataloget, er den gamle kending tags/kategorier.
StumbleUpon popper en form når man rater et site der ikke er i deres indholdskatalog og denne form kræver blandt andet, at man tilføjer sitet til en kategori og gerne også tildeler tags og dét fungerer ikke optimalt. Når jeg er i mit lettere rastløse stumble-mode er jeg altså ikke voldsomt disponeret for at bruge tid på at scrolle gennem alfabetiserede kategori-lister samt tildele meningsfulde tags.
Men nogen skal jo tildele beskrivende metadata der muliggør oplevelsesorienteret filtrering. Og Google, Delicious, Technorati osv. er jo mere til når man allerede véd hvad man går efter og så kræver det en mere aktiv/bevidst indsats at søge. Det jeg elsker ved StumbleUpon er det tilfældige, automatiserede, “I-feel-lucky-agtige” inden for afgrænsede emne-kataloger hvis indhold er kvalitetssikret af interesse-fæller (“andre som mig” ).
Hvordan får vi bedst filtreret og bedømt alt det gode indhold på web, og tror I man kan undvære det menneskelige aspekt og lade algoritmer (Calais, Evri) sortere skidt fra kanel ? – lad os høre nogle kommentarer.
– Rasmus Lasthein
Google lancerer Social Graf API
Murene omkring Facebook og Myspace er under massivt pres. Den sidste måned har handlet om dataportability, som handler om at skabe standarder, der kan lade os tage vores sociale data med os rundt.
Og nu lancerer Google i dag så det såkaldte Social Graph API, hvor de har brugt deres kæmpe søgeapparat til at søge disse sociale data frem.
Det vil sige at Google ud fra en søgning af webben kan genskabe hvad jeg interesserer mig for, og hvem der er mine venner ved at kigge på mine links.
Tjek det ud i denne præsentation på Youtube:

Potenttialet i denne teknologi er stort.
Selvom alle de rigtigt tænkte standarder i Dataportability projektet sikkert i teorien leverer bedre data, så kan det jo godt ligge lidt tungt med at få de rigtige kodestandarder til at blive til noget sådan rigtigt på nettet. Når jeg tænker på hvor mange år man snakkede om XML før det for alvor blev nyttigt!
Google lancerer her noget der dur fra dag et, uden at en hel masse mennesker skal til at ændre deres websites eller deres adfærd.
– Jens Poder
WOT – brugergenereret tillidsbarometer til internet

Det her er rigtig interessant. Dette plugin til Firefox tillader bruger hurtigt og enkelt at rate et website for, i hvor høj grad de har tillid til det.

Når brugerne ser et linket i deres browser, er der en lille ring ved siden af, der giver oplysning om hvor stor tillid brugerne har til dette site.

Omtale fundet på Haklabs.
– Jens Poder
Tag2Find: Tagging til dit Windows Desktop

Det her ser meget lovende ud – og godt nytår iøvrigt!
Jeg ved ikke om jeg er den eneste der har et problem med at filer i windows kun kan ligge i en mappe. Jeg har prøvet uendeligt mange systemer af filtræstrukturer i på min harddisk, men altså… jeg er aldrig blevet helt tilfreds. Nu kører jeg barer med månedsmapper ala “2007 01”, og så søger jeg filer frem via den hurtige fil-søge-database X1.
Men jeg har hele tiden manglet muligheden for at lade filer indgå i flere forskellige tematiske grupper. For eksempel har jeg lyst til at have et indscannet visitkort på en samarbejdspartner i en mappe der hedder kontakter, men jeg vil gerne samtidig kunne tilknytte kortet til en samling af filer der tilhører det projekt jeg arbejder sammen med vedkommende på.

Det er spændende at se, hvordan tags har bevæget sig fra internettet til vores desktops. Web 2.0 begynder at påvirke og inspirere, hvordan vores PC’ere bliver skruet sammen.
Jeg venter at få en beta-adgang en af dagene, og så vil jeg teste det grundigt igennem og skrive en anmeldelse.
– Jens Poder
technorati tags:desktop_hack, tags, tagging, desktop
Bladre bladre bladre, ah ja!
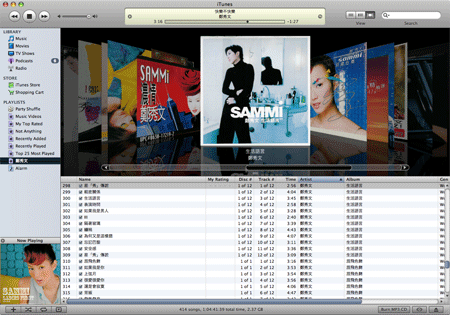
Hvor er det dog dejligt med den nye coverart bladrefunktion i iTunes. Lidt mærkeligt det først kommer nu, når vi efterhånden i en årrække har vidst at brugerne primært husker i billeder, dufte, stemninger, relationer osv., og at alfabetiserede indexlister meget sjældent virker hverken særligt inspirerende eller er til megen hjælp når man søger en kunstner hvis navn man ikke lige kan huske!
Men godt det omsider kom, og i en rigtig lækker udgave i øvrigt, og hvor må det være rart for Apple at få så mange metadata-relationer frit og kvit foræret fra brugerne. Jeg har sagt ja til tilbuddet om gratis at kunne downloade coverart for de temmelig mange CD’er jeg har lagt ind i iTunes, så nu ved Apple pludeslig rigtig meget mere om mit musikforbrug. Godt for dem!
En af de mange diskussioner der har kørt om Murdochs køb af Myspace gik jo netop på at han derved ville få en fantastisk indsigt i brugernes relationer i forhold til forbrugsmønstre. Med andre ord indsigt i f.eks. hvilke aldersgrupper hvor fans af Barenaked Ladies også lytter til Beyonze .
Man kan vel næsten sige at Apple, udover at komme brugerne i møde, har fået en lille Murdoch oven i hatten. Lad os håbe det så kommer til at afspejle sig i iTunes anbefalinger der indtil videre begrænser sig til et lidt fattigt kollaborativt filter og iMix. Personligt ville jeg da gerne præsenteres for kunstenere der på ægte Long Tail manér dukker op som relaterede emner “via” andre brugeres CD samlinger.
– Rasmus Lasthein
Metadata à la carte
En af mine faglige kæpheste er datamining på metadata-relationer og meningsfulde, multimodale, grafiske visninger af disse sammenhænge.
I informations-tsunamien vil grænseflader der indbyder til “peripheral sensing” være en af de redningsplanker der kan redde brugerne fra druknedøden 😉
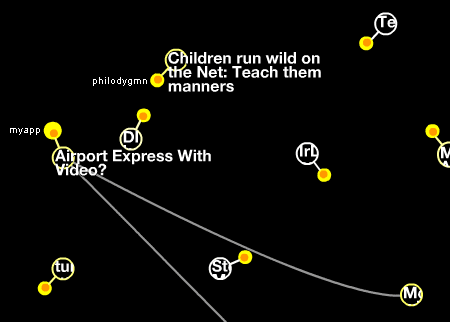
Digg Labs har lavet denne lækre, lille ting de kalder Swarm. Den minder lidt om WeFeelFine som jeg omtalte for nogle uger siden med den forskel at det selvfølgelig er aktive historier der sværmer. Der er tre filtre/modes og de mangler en del i at være rigtigt brugbare hvis de skal kunne anvendes i forhold til perifær sansning af informationsflow. Men det er godt at se at der nu (igen) begynder at dukke små metadata-gardens op.
Når vi nu ved at ca. 90% af kommunikationen mellem to mennesker der står over for hinanden er ikke-verbal vil det så ikke være naturligt at ekstrapolere denne viden til online oplevelser designet og optimeret til en høj grad af ikke-tekstuel aflæsning ?
Jeg tror personligt det vil være en absolut nødvendig udvikling for en række indholdsformater til nettet såfremt vi ikke skal udvikle os til en race af stressede, skrålæsende, nøgleordsskimmende semantikere.
– Rasmus Lasthein

2 comments